ゲンゴカ・ラボ 講座レポート
特別講座「AIは誰のことばを学んでいるのか? ~AIと不正義~」
板津木綿子(東京大学大学院情報学環・学際情報学府教授)
講義日 2025-10-30
第5回目の講義は、『AIは誰のことばを学んでいるのか?AIと不正義』をテーマに、東京大学大学院情報学環の板津木綿子先生によるものです。 2022年11月、アメリカのスタートアップ企業OpenAI社が発表した対話型AI「ChatGPT」は、2ヶ月で1億ユーザーを突破するなど、今までに類のないペースで普及しました。大規模言語モデルを活用した昨今のAIは、日常会話のように身近な言葉を交わすことで、私たちにとって非常に身近な存在になりつつありますが、そのAIは、果たして誰の言葉を学習しているのでしょうか。
※本記事は、すぎなみ大人塾総合コース「ジブン・ラボ」シリーズ2025『ゲンゴカ・ラボ』で行われたカリキュラムより抜粋・再編集したものです。
このレポート記事は、実際の講座内容をもとに要約したものです。実際の講座内容が気になる方は、ぜひ動画をご覧ください。
目次
私(板津木綿子)は、いわゆるAIの技術者ではなく、主な研究のテーマはアメリカの歴史学・文化史・社会史です。幅広いテーマのように思われるかもしれませんが、移民や性的マイノリティ、ジェンダーといった「社会の端に追いやられている人たち」についての研究を続けてきました。
そんな私がAIに携わるようになったのは約6年前(2019年)からです。
あるIT企業と東京大学が共同事業を行うことになり、学内で参加希望者を募った際に数名の教授たちと手を挙げました。
平等な社会を実現するためにAIの技術をどのように使えるか?
AIの技術は平等な社会の実現においてどのような障壁となるのか?
そのようなことについて、日々研究しています。
AIを理解する入り口。技術は善悪を併せ持つ
初めに、「技術の発明」と「実際の使われ方」の間にはギャップがあることについてお話します。

[講座スライドより]
若い方にはあまり馴染みがないかもしれませんが、かつて「タイプライター」と呼ばれるものがありました。タイプライターとは、文字盤を打つことで活字を紙に印字することができる機械で、もともとは目が見えない友人のために作られたと言われています。しかしながら、実際の使われ方は目が見えない人のためではなく、手書きだった当時の「出版効率を上げる」ために爆発的に普及しました。
実は「自動運転技術」も似たような背景を持っていて、もともとは自動車を運転できない身体的特徴を持っている方が自立的に移動できるように、という発想から生まれていますが、今では「これまで自動車を運転していた人が、運転しなくて済むようになる」という側面にばかりフォーカスがあたっていますよね。
つまり、「最初の発想理由」と「その後の広まり方」には隔たりが生まれる。科学技術というものは、もともとの思惑と異なる方向に思わぬ形で広まることがあるんです。
そしてもう一つ。技術の使われ方には「プラス」と「マイナス」両方の側面があります。分かりやすい例でいうと、原子力の技術です。効率良くエネルギーが生み出せるプラスの側面があれば、戦争の道具として使われるマイナスの側面もあります。AI技術も同様で、使い方次第でプラスにもマイナスにも働く、両方の可能性を内包しています。
AIの技術革新は、これまでにいくつかのフェーズを経ていて、現在は大量なデータを学習し、そのパターンを認識することで、次に来る言葉や色、形を予測して確率的に高いものを表示できるようになりました。例えば、「明日は雨が」と入れると、「降るだろう」という言葉が続くことを予測できるようになったんです。
すでに社会では、企業や自治体でもAIが活用され始めていて、業務タスクを自律的に実行できるまでになっていますが、実際のところAI技術にはまだまだ未熟なところがあります。
AIは外れ値を取りこぼし、「典型例」を見つける
現在のAIの仕組みを理解するための簡単な実証結果をご紹介します。
例えば、生成AI ChatGPTを使って、「犬を描く人」と「人を描く犬」の2種類の画像生成をお願いしてみました。

[講座スライドより]
すると、「犬を書く人」は上手に表現できましたが、「人を描く犬」は、手の部分が人間の手になっていて不十分な結果になりました。なぜこうなってしまうかというと、AIのデータベース上に「人を描く犬」が存在しないからなのです。そのため、「何かを描く」ように指示すると絵を描く主体は「人間(の手)」になってしまうという訳です。
もう1つ、「時計の文字盤」の画像生成をお願いしてみました。
指示文としては、「腕時計を書いてください。時計の針は2時15分にしてください」と書きました。その結果、下の図の左の出力のように、時間の表示を間違えた画像が生成されました。
なぜこうした生成結果になったかというと、実はネットで「時計」と検索すると大体が「10時10分」を指した画像がでてきます。これは時計の広告などで、最も時計盤が美しく見えるシンメトリーな状態がその時刻のため、インターネット上に大量にその時刻の画像が溢れているためです。だから「2時15分」と言っても、10時10分を指している画像が出てきてしまうんですね。

[講座スライドより]
念のため数日後にもう一度試したところ、同じように「10時10分」の画像が出てきたので、さらに「10時10分ではなく、2時15分にしてください」と改めて指示しましたが、2時15分の画像は生成されませんでした。この検証結果から分かるのは、AIは「典型例を探すのが得意だ」ということ。裏を返せば、典型例以外のものは全て「外れ値」扱いになってしまうということです。
(追記:2026年4月に再度試したところ、2時15分と表示できるようになっていました。)
ですが、私たちが暮らす社会には多様な人が存在しています。そんなさまざまな人たちが存在する社会において、典型例ばかりを探すAIはどういった影響を及ぼすのでしょうか。
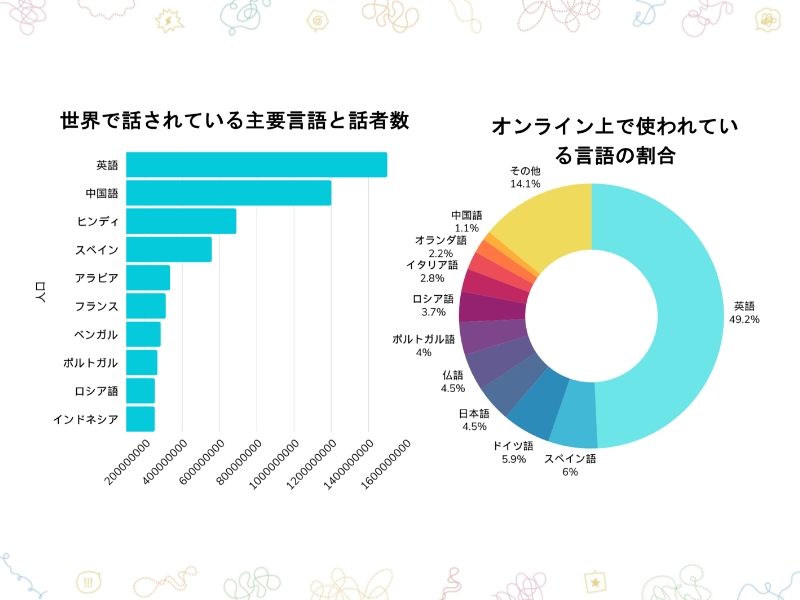
[講座スライドより]
この資料は、世界で話されている主要言語と話者数を示しています。英語が約15億人、次いで中国語、北京語が12億人、ヒンディー語が約6億人、スペイン語は5億人と続きます。右側は、オンライン上で使われている言語の割合を示していますが、なんと、インターネット上で私たちがアクセスできる情報の約半分は英語なんです。
つまり、世界の人口(約80億人)の内、英語を話しているのは約15億人でしかないにも関わらず、オンライン上にある情報としては、英語が半分を占めてしまっている。日本語を見ると4.5%、それからポルトガル語、ロシア語、イタリア語、オランダ語と続きます。
この結果から、英語にかなり偏ったデータを取り込んで、大規模言語モデルの生成AIが作られていることがよく分かります。実際の話者とオンライン上にあるデータ量は比例しておらず、そこには偏りがあるということです。
では、その影響はどこにあるのか。少しずつ不正義の話に入っていきたいと思います。
偏ったデータが生む「不正義」
次に紹介したいのが、AIの識別管理の研究です。識別管理とは、人を見分けるために使うAI技術のことで、身近な例でいうとスマートフォンの顔認証があります。もしかすると皆さんの中にも、オフィスの入口にカメラがあり、顔認証が社員証の代わりになってゲートが開くという職場で働かれている方もいるかもしれません。セキュリティを高め、私たちの安心・安全を担保してくれる、かつ利便性が向上するようなAIの使い方ですね。
しかしながら、そのような識別管理が安心・安全を与えない場合もあります。それがこの研究で、「人種やジェンダーによって顔認識の技術に精度の差がある」という結果が発表されました。AIは白人の男性の写真を最も多く取り込んでいるため、白人の男性の顔の識別の精度は高いのですが、黒人の男性、それから白人の女性の順に、少しずつ精度が下がっていきます。特に、肌の色の濃い女性は68.6%の精度だったという衝撃的な結果がでました。この2018年の結果を踏まえて改善は進んでいるものの、今現在精度は100%ではありません。
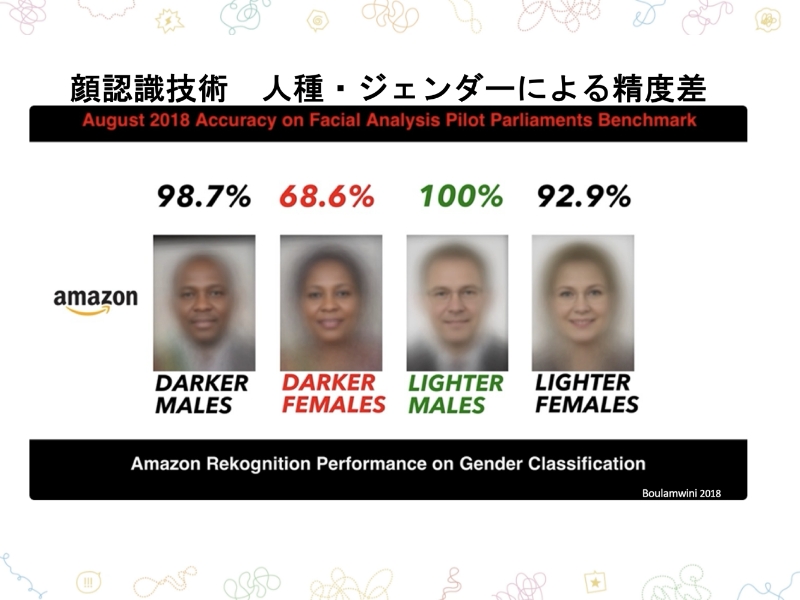
[講座スライドより]
もし、こうした100%の精度ではない技術を、例えば警察や公安当局といった公的機関が使ったとしたら? AIが間違えて「この人が犯人です」と照合してしまったとしたら? 何もしていない無実の人が誤って逮捕されてしまいますし、実際にそうしたことが起きているんです。
数日前にアメリカの番組で報道されたのですが、16歳の少年がポテトチップスの袋を持っていたところ、近くの防犯カメラの照合システムが間違えて、「ポテトチップスの袋」を「銃」と認識してしまい、警察がやってきたという事案が起こりました。しかも、少年は誤って手錠をかけられてしまったんです。人間であれば、銃とポテトチップスの袋が似てないことは容易に分かりますが、AIだとそういった間違いも起きてしまう。16歳の未成年の子どもにそのようなことが起こるのも、人権的観点から見れば相当なトラウマになりかねません。
また、アメリカではすでに裁判所、司法制度の中でもAI技術が使われています。何に使われているかというと、裁判官が「この人は再犯をするだろうか?」「同じように罪を繰り返すだろうか?」という再犯率を計算する時に使っているんですね。
例えば、下の図の2人は全く同じ罪で逮捕され、罪の重さは同じにも関わらず、1人には26年の刑、もう1人には2年の刑という量刑を裁判官が言い渡しています。このような裁判記録をAIは学習しています。

[講座スライドより]
何の違いがあるかというと、「肌の色」です。これまで人間の裁判官による裁判記録において、暗黙の人種差別が含まれているものだったために、過去の裁判記録を学習したAIは「黒人は罪が重くなる」と学習してしまいます。
「AIはデータに基づいているから客観的に違いない」とつい思い込んでしまいがちですが、実際はどのようなデータを読み込ませているか、どういった学習をさせているのかを人間が管理しなければ、こういった過ちが起きてしまうんです。
最近では空港においても入国審査が顔認証で済み、パスポートもほとんどが電子化され、効率化が図られています。ですが、人がいないということはそれだけ私たちが信用されているということではなく、誰か(もしくは機械)がどこかで見ているということ。空港の中にも多くの監視カメラが設置され、便利さと引き換えに私たちは何を失っているのかを考えなければなりません。
エネルギー、水、環境。地球規模の「不正義」
さらに、別の観点から考えてみたいと思います。
対話型AIはとても便利で、使っている方も多いかと思いますが、実はものすごいエネルギーを使っています。
100語のメールを書くのに、約500mlの水が必要だと言われています。なぜこれほどの水が必要なのかというと、データセンターという場所に、大量のパソコンが並んでいるのですが、世界中のユーザーが使えば使うほど熱を持つわけです。それを冷却するために水が必要になり、冷房を使うにしても結局のところ水が必要になります。ウルグアイでは、真水が水道から出なくなってしまうくらいの大規模干ばつのなか、データセンターを建設するということで、大規模なデモが起こったという報告もされています。
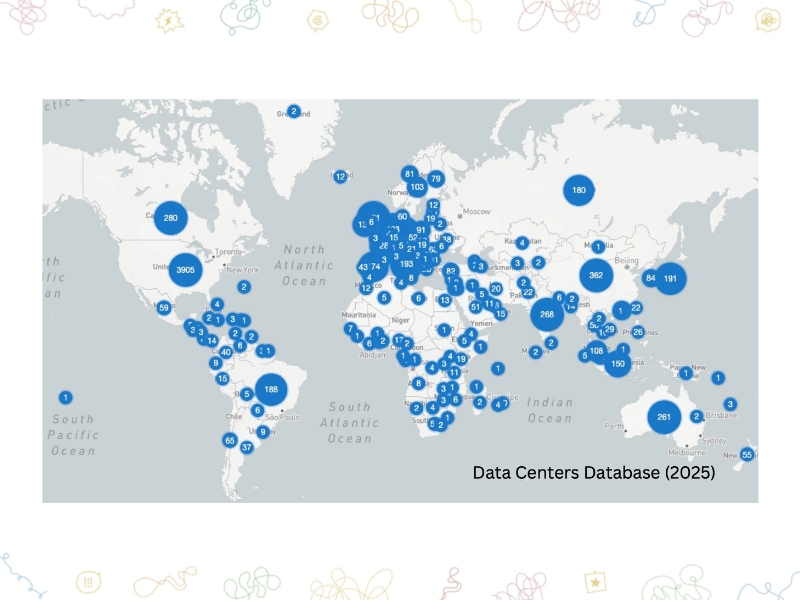
[講座スライドより]
それから、生成AIが一日あたりに消費する電気使用量も試算されており、アメリカの場合では3万3000世帯の電気使用量に相当すると言われています。ユーザー数が増加している現状を見ると、今後電気使用量はますます増えていくでしょう。
このように、ただ生成AIを使っているだけでは想像できない裏側のこととして、こんな話もあります。
私たちは普段スマホの画像やSNSの投稿などで、見ただけでトラウマになるほどショッキングで、心理的害を及ぼすものはそれほど見かけません。理由は、AIが不適切だと判断して表示しないように弾いてくれているからで、データ全体の約98%に相当します。では、残りの2%はというと、グレーゾーンのため人間の目で見て判断し、AIに新しく学習させているのです。それを誰がやっているのかというと、主にアジア、アフリカの労働者が安価な賃金で行っています。私たちは、便利になることの裏側に、このように心理的な負荷を感じながら働いている人がいることを忘れてはいけないと思います。

[講座スライドより]
また、アメリカのグローバル・マネジメント誌『ハーバード・ビジネス・レビュー』によると、アメリカでのもっともポピュラーなAIの使われ方は「話し相手」だと発表されました。擬似的なカウンセラーとして使っている人が約4割いたということです。
「人間対人間」の対話は煩わしいことも多いですが、生成AIは必ず相談者を肯定し、否定しない、裏切らない、意地悪もしない。そういうやり取りのほうが楽だと思います。でも、人間同士は分かりあえないからこそ言葉を尽くして、思っていることを正確に伝えようと試行錯誤します。
AIとの対話が楽だと思い、AIとの会話だけに慣れていってしまうと、人間との対話におけるルール、言葉の使い方や言い回しができなくなってくるのではないかという不安もあります。人それぞれ様々な特徴があるため、スムーズな意思疎通ができなくても、言葉を尽くしながら心を通わせようとする。そこに意味や価値を見出さなければ、言葉の持つ意味が衰えてくるのではないかと私自身は危惧しています。
「典型例」を見つけるAIへの抵抗
最後に、生成AIのバイアスについてお話しします。
例えば、AIに「飛行機の乗務員の画像を生成してください」と依頼すると必ず「女性」の画像が生成されます。これが意味するのは、AIは「この職業は男性」「この職業は女性」とハッキリ描き分けてしまうということです。
それは、実際の社会の中で「飛行機の乗務員=女性」という認知(=偏見)が存在していて、それを反映しているからです。このような偏りは、「職業」だけではなく、世の中の偏見や価値観の数だけ存在しています。
そうした状況に対して、アメリカの大統領府は2025年7月に『AIアクションプラン』を発表しました。この中に「私たちのAIシステムはイデオロギーのバイアスから解放されなければならない」という文章が2回ほど出てきます。つまり、大規模言語モデルの価値観を「誰」が作っているのかということを、私たちは意識的に考えなければなりません。

英語圏や儒教圏、またカトリックやイスラム教など、さまざまな世界中の価値観の中で、現状の生成AIの価値観がどれに近いかを示した研究[講座スライドより]
このように、生成AIにはさまざまな点において価値観の偏りが見られますが、こうしたモデルの価値観に対して、抗う取り組みしている団体もあります。ここでは、「ジェンダーバイアス」に関連する2つの動画をご紹介します。
1つ目は、職業によってジェンダーが明確に分かれてしまうことに対して、データをより多様にさせる取り組みを行っている団体の動画です。動画内では、女性の科学者の画像をたくさん生成し、かつ「女性科学者」というラベルを貼るのではなく、「科学者」というラベルを貼ることによって「科学者」の多様化を図っています。言葉の持つイメージ、不正義に対して抗っている例です。
2つ目は、こちらのサッカーの動画です。
前半は、フランスの男子サッカーチームのスーパープレーがたくさん出てきます。そして映像の最後には「この感動を与えてくれるのは、Les Bleus(フランス男子代表の愛称)だけ」というメッセージが出てきます。それに続いて、「あなたたちが今見ていたのは彼らではない」というメッセージが出て、先ほど見ていた男子選手のスーパープレーは、実はすべて女子選手のディープフェイク映像であったことが明かされます。
私たちは、サッカーにおけるスーパープレーというと、つい男子サッカーを思い浮かべてしまいますが、そういった先入観にハッと気づかせてくれる動画です。
冒頭に申し上げたように、技術というのは、あくまでも人間がどのように使うか次第で変わります。AI技術を社会全体としてどのように使っていくのか、私たちは今こそ考えていかなければならないと思います。



